BMW Garage Startup Program PoC
프로젝트 개요
BMW Startup Garage는 개발, 생산, 서비스 등의 부분에서 4차 산업 기술과 비전을 자동차 산업과 함께 파트너사를 선정하는 프로그램이며, 1차 제안서 검토 후 선정된 제안서 중 주어진 기간 동안 PoC 검증 기간과 심사를 거쳐 파트너사를 선정하게 됩니다. 월 별, 차량 별 핵심 키워드를 도출하여 핵심 이슈 파악을 도울 수 있는 고객 상담 데이터를 위한 대시보드을 제안하고 선정되어 PoC 프로젝트에 참여하게 되었습니다.
프로젝트 구성
고객 상담 이력 대시보드의 주요 기능
- 상담 주제 별 카테고리 분류 및 시각화
- 차량모델 별 주요 키워드 랭킹, Wordcloud 시각화
- 일자, 상담 주제, 모델 별 고객 상담 데이터 조회
- 고객 이슈 별 상담원 답변 내용 분류
아키텍처
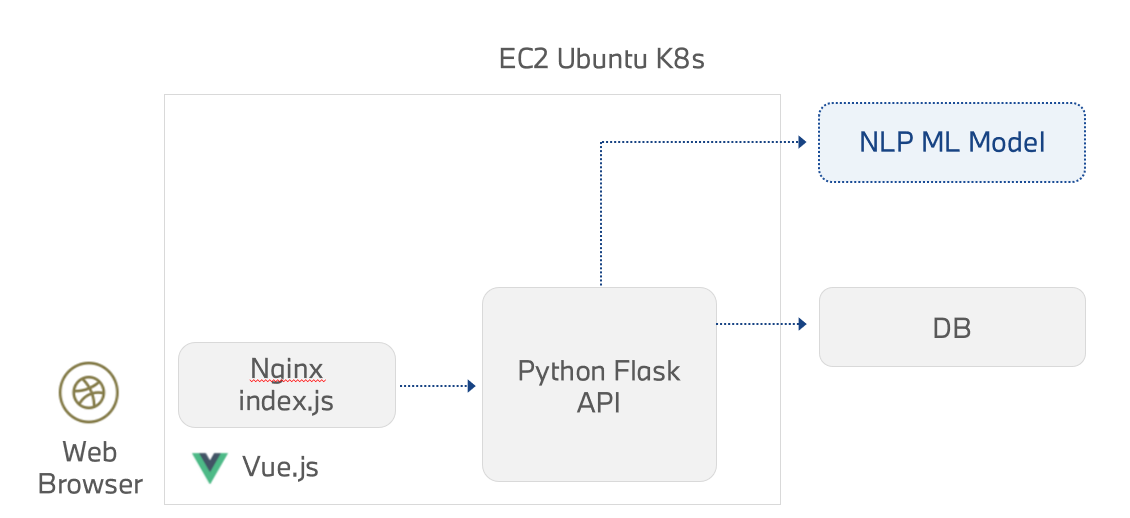
아키텍처 배포

담당역할
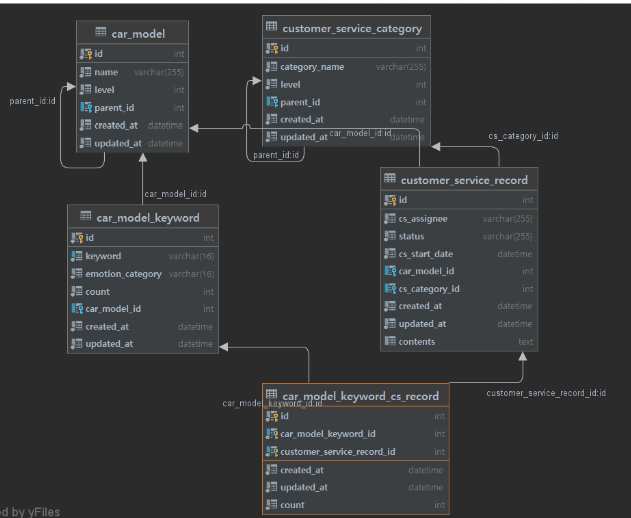
대시보드 테이블 설계
대시보드의 사용될 테이블 정의 및 테이블 설계 하였습니다. ERD 및 테이블 정의서 문서로 작성하여 관리하였습니다.
데이터 전처리
BMW로 부터 제공 받은 Raw Data을 다음과 같이 스케일링 및 재가공 하였습니다.
중복 데이터 제거
제공 받은 데이터 중 동일한 내용의 상담 내용이 다수 발견되었습니다.
발견된 중복된 데이터를 전부 삭제하였습니다.
이상치 확인 및 제거
상담내용 중에 특정 카테고리에 관련 없는 내용과 “잘못 누름” 같은 내용을 이상치로 판단하여 제외 하였습니다.
맞춤법 검사 및 데이터 정형화
상담내용 데이터 중 오탈자가 다수 발견되어 py-hanspell을 활용하여 맞춤법, 띄어쓰기 재교정 하였습니다. 유사 단어 리스트를 작성하여 통일하게 정형화 하였습니다.
예시)bmw, Bmw → BMW, 5 시리즈, 5 series → 5 Series
개인정보 가명 처리 및 삭제
제공 받은 Raw Data에 상담사 이름, 고객 이름, 차량 시리얼 넘버 등 개인정보 가명 처리가 되어 있지 않아 삭제 하였습니다.
BMW 대시보드 전용 불용어 사전 구축
기존 오픈소스 불용어 사전에 대시보드에서 불필요한 불용어 사전을 추가하여 별도 커스텀 불용어 사전을 구축 하였습니다.
전처리 전 예시

전처리 후 예시

AWS RDS 데이터 적재
테이블 설계 기반으로 AWS RDS에 테이블 생성 및 전 처리한 데이터 각 테이블에 맞게 파싱하여 데이터 적재 진행 하였습니다.
AI 학습 데이터 셋 구축
카테고리 분류을 위해 Kobert 모델이 학습할 수 있게 각 카테고리 별로 학습 데이터를 구축하였습니다.
프로젝트 회고
BMW에서 제공한 데이터를 받았을 때 정말 앞이 깜깜 했었습니다. 상담사 마다 기록하는 방식이 전부 달라서 이걸 어떻게 규격화 해서 키워드를 도출 할까 고민을 많이 했습니다. 데이터와 관련된 업무는 혼자 전부 처리 해야 했고 파싱한 데이터를 가지고 웹에 결과물로 나오기 때문에 한편으로 스트레스가 많았습니다. 불용어 사전을 구축과 정규식을 조합해보면서 규칙을 찾고 처리하는데 많은 시간을 쏟았습니다. 형태소 분석을 통해 유의미한 키워드가 도출될 때 책임감 있게 업무를 수행 했다는 뿌듯함이 컸습니다.
한편으로 데이터 핸들링에 집중 하느라 인프라, 개발, 배포 관련하여 업무를 경험 해보지 못해 아쉬움이 컸습니다.