음성인식 키오스크 말로해
프로젝트 시연
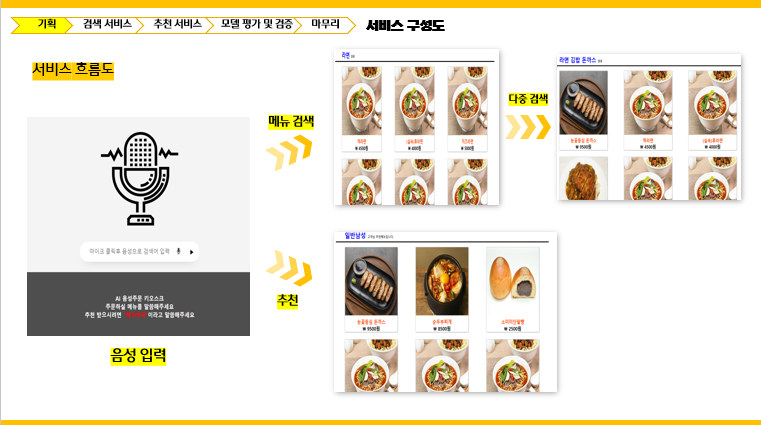
메뉴 검색
메뉴 추천 서비스
프로젝트 개요
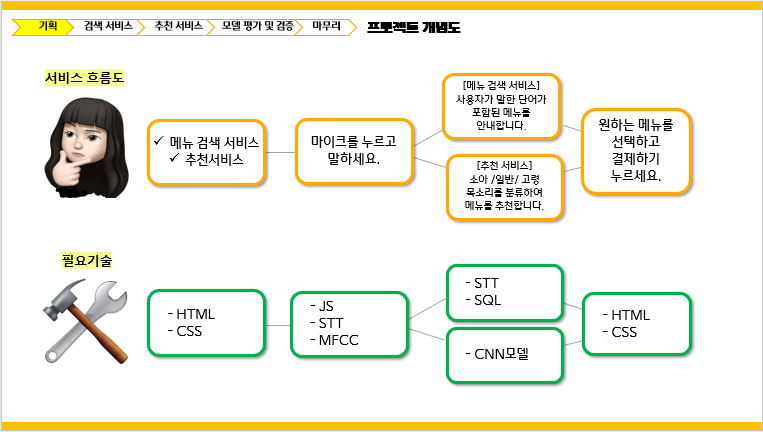
STT 기술을 이용하여 고객이 키오스크에서 음성으로 주문하고 고객의 음성을 분석, 분류하여 맞춤 상품을 추천하는ToyProjects 진행 하였습니다.
음성의 분류는 다음같이 6개 분류로 구분하였습니다.
- 소아 - 남
- 소아 - 여
- 일반 - 남
- 일반 - 여
- 노인 - 남
- 노인 - 여
프로젝트 구성
담당역할
음성 데이터 전처리
데이터 수집
데이터는 AI 허브에서 수집하여 사용하였습니다.
자유 대화 음성 데이터 셋으로 소아 남여, 일반 남여, 노인 남여를 수집하였습니다.
데이터 스케일링
수집한 데이터의 시작점 길이가 전부 불규칙하여 앞 부분의 약 2초정도 잘라 데이터의 시작점을 맞추었습니다.
학습 데이터 구성
사람에 따라 “안녕하세요”라고 하더라도, 어떤 사람은 1초, 어떤 사람은 3초가 걸릴 수도 있기 떄문에 MFCC 알고리즘을 사용하여 퓨리에 변환을 한 특징을 추출하여 데이터을 구성하였습니다.
음성 분류 모델 개발
모델선정
데이콘에서 진행한 음성 분류 AI 해커톤에 공유된 소스와 한국어 음성을 이용한 연령 분류 딥러닝 알고리즘 기술 개발에 작성된 논문을 참고하여 CNN 모델을 선정 하였습니다.
모델 개발 및 검증
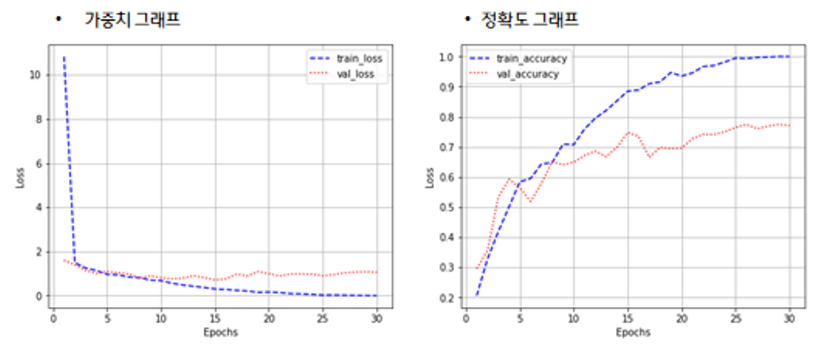
모델 개발은 Keras 사용하여 오픈소스 참고하여 모델을 구현하였습니다. 모델의 검증은 수집 된 데이터가 한정 적이고 대량의 데이터가 아니기 때문에 K겹 교차검증을 선택하여 검증하였습니다.
모델 평가
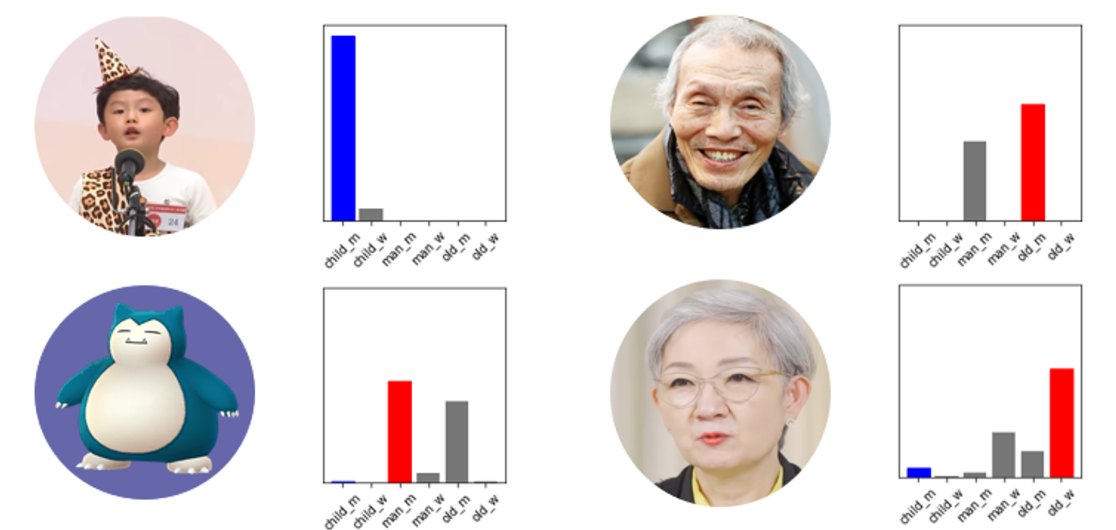
학습된 모델을 별도로 저장 후 기존 수집 된 음성이 아닌 YouTub에서 케이스 별로 음성을 직접 수집하여 학습된 모델에 분류를 진행하였습니다. 소아의 경우는 높은 유사도가 높게 분류를 잘하는 편이고 일반 남성과, 노인은 유사도가 비슷하게 나오지만 정확하게 분류하였습니다.
 _캐릭터는 작성자를 대신한 임시 캐릭터 입니다. _
_캐릭터는 작성자를 대신한 임시 캐릭터 입니다. _
프로젝트 회고
프로젝트를 진행하면서 모델링, Django 활용 한 웹 페이지 개발 등 다양한 분야에서 Python 사용 할 수 있게 되었습니다. 아쉬웠던 부분은 텐서플로우의 케라스를 사용하여 라이트하게 모델을 만들었던 점과 웹 페이지를 실제 배포까지 해보지 못한 점이 너무 아쉬웠습니다. 또한 학습된 모델이 노이즈가 없는 깨끗한 음성을 기반으로 학습되어 주변소음에 영향이 있다는 점을 개선 하지 못했습니다. 다음 기회가 있다면 주변의 소음 영향이 없게 개선 하며 소아, 일반, 노인이 아닌 연령 별로 구분하여 AWS에 배포까지 해보고자 하는 마음이 있습니다.
참고자료
코드 참고
참고논문